本文同步自银河实验室博客。
之前,银河实验室对基于unicorn的模拟执行fuzzing技术进行了研究。在上次研究的基础上,我们进一步整合解决了部分问题,初步实现了基于Unicorn和LibFuzzer的模拟执行fuzzing工具:uniFuzzer。
关于这项研究的相关背景,可回顾实验室之前的这篇文章基于 unicorn 的单个函数模拟执行和 fuzzer 实现,这里就不再缀述了。总体而言,我们想要实现的是:
- 在x86服务器上模拟运行MIPS/ARM架构的ELF(主要来自IoT设备)
- 可以对任意函数或者代码片段进行fuzzing
- 高效的输入变异
其中前2点,在之前的研究中已经确定用Unicorn解决;输入的变异,我们调研后决定采用LibFuzzer,并利用其代码覆盖率反馈机制,提升fuzzing效率。
在这篇文章中,我们先简要介绍下Unicorn和LibFuzzer,随后对模拟执行fuzzing工具的原理进行详细的分析,最后通过一个demo来介绍工具的大致使用方式。
背景介绍
Unicorn
提到Unicorn,就不得不说起QEMU。QEMU是一款开源的虚拟机,可以模拟运行多种CPU架构的程序或系统。而Unicorn正是基于QEMU,它提取了QEMU中与CPU模拟相关的核心代码,并在外层进行了包装,提供了多种语言的API接口。
因此,Unicorn的优点很明显。相比QEMU来说,用户可以通过丰富的接口,灵活地调用CPU模拟功能,对任意代码片段进行模拟执行。不过,我们在使用过程中,也发现Unicorn存在了一些不足,最主要的就是Unicorn其实还不是很稳定、完善,存在了大量的坑(可以看Github上的issue),而且似乎作者也没有短期内要填完这些坑的打算。另一方面,由于还有较多的坑,导致Unicorn底层QEMU代码的更新似乎也没有纳入计划:Unicorn最新的release是2017年的1.0.1版本,这是基于QEMU 2的,然而今年QEMU已经发布到QEMU 4了。
不过,虽然存在着坑比较多、QEMU版本比较旧的问题,对我们的模拟执行fuzzing来说其实还好。前者可以在使用过程中用一些临时方法先填上(后面会举一个例子)。后者的影响主要是不支持一些新的架构和指令,这对于许多IoT设备来说问题并不大;而旧版本QEMU存在的安全漏洞,主要也是和驱动相关,而Unicorn并没有包含QEMU的驱动,所以基本不受这些漏洞的影响。
QEMU
关于QEMU的CPU模拟原理,读者可以在网上搜到一些专门的介绍,例如这篇。大致来说,QEMU是通过引入一层中间语言,TCG,来实现在主机上模拟执行不同架构的代码。例如,如果在x86服务器上模拟MIPS的代码,QEMU会先以基本块(Basic Block)为单位,将MIPS指令经由TCG这一层翻译成x86代码,得到TB(Translation Block),最终在主机上执行。
而为了提高模拟运行的效率,QEMU还加入了TB缓存和链接机制。通过缓存翻译完成的TB,减少了下次执行时的翻译开销,这即就是Unicorn所说的JIT。而TB链接机制,则是把原始代码基本块之间的跳转关系,映射到TB之间,从而尽可能地减少了查找缓存的次数和相关的上下文切换。
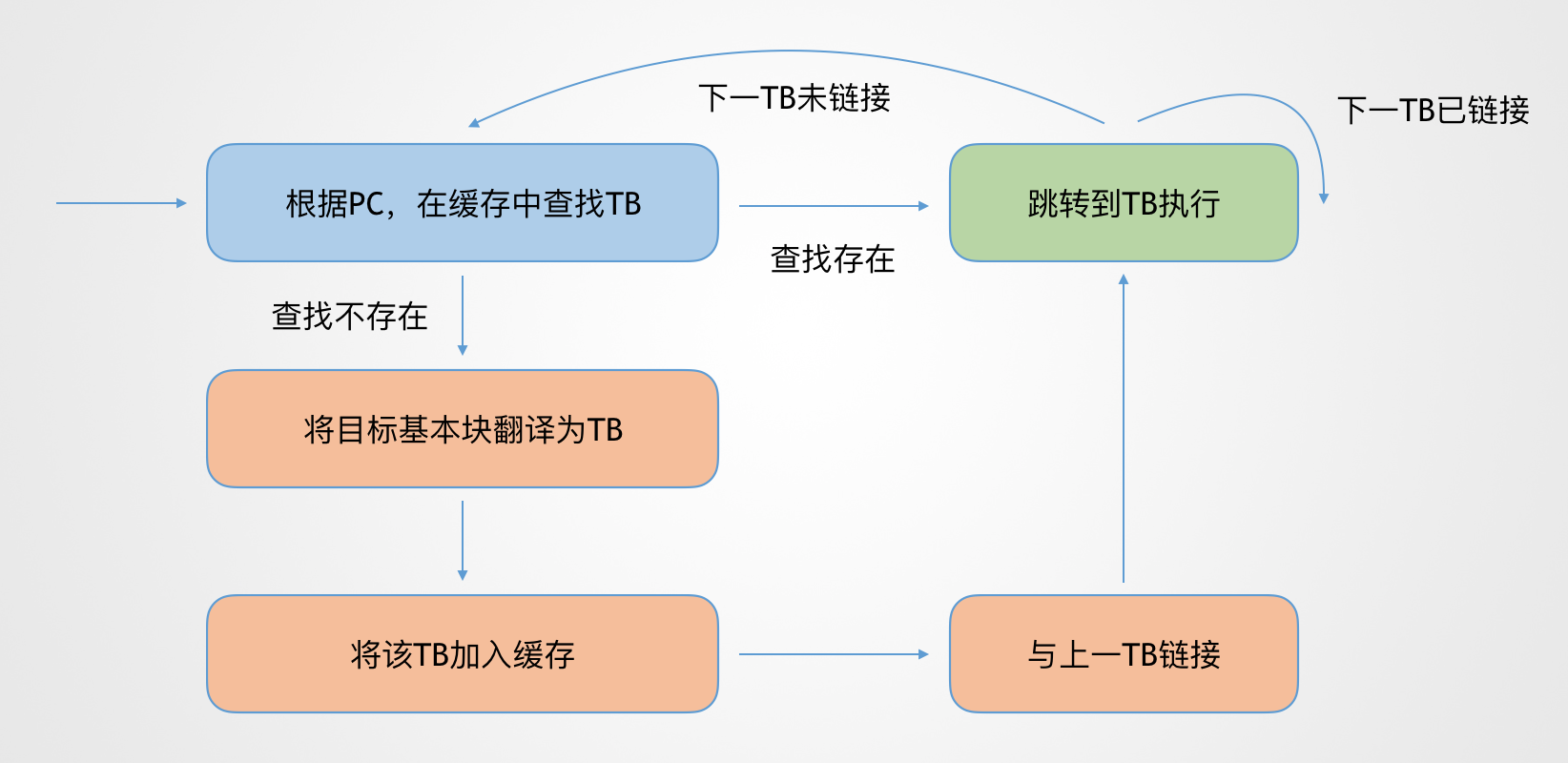
值得一提的是,Unicorn所提供的hook功能,就是在目标代码翻译成TCG时,插入相关的TCG指令,从而在最终翻译得到的TB中,于指定位置处回调hook函数。而由于TCG指令和架构无关,因此添加的TCG指令可以直接适用于不同架构。
LibFuzzer
LibFuzzer应该许多人都不陌生,这是LLVM项目中内置的一款fuzzing工具,相比我们之前介绍过的AFL,LibFuzzer具有以下优点:
- 灵活:通过实现接口的方式使用,可以对任意函数进行fuzzing
- 高效:在同一进程中进行fuzzing,无需大量
fork()进程 - 便捷:提供了API接口,便于定制化和集成
而且,和AFL一样,LibFuzzer也是基于代码覆盖率来引导变异输入的,因此fuzzing的效率很高。不过,这两者都需要通过编译时插桩的方式,来实现代码覆盖率的跟踪,所以必须要有目标的源代码。接下来,在uniFuzzer的原理中,我们会介绍如何结合Unicorn和LibFuzzer的功能,对闭源程序进行代码覆盖率的跟踪反馈。
uniFuzzer原理
uniFuzzer的整体工作流程大致如下:
- 目标加载:在Unicorn中加载目标ELF和依赖库,并解析符号
- 设置hook:通过Unicorn的基本块hook,反馈给LibFuzzer代码覆盖率
- 准备环境:设置栈、寄存器等信息
- fuzzing:将Unicorn的模拟执行作为目标函数,开始LibFuzzer的fuzzing
下面对各环节进行具体的介绍。
目标加载
遇到的许多IoT设备,运行的是32位MIPS/ARM架构的Linux,所以我们初步设定的目标就是这类架构上的ELF文件。
如实验室之前对模拟执行研究的那篇文章中所讲,我们需要做的就是解析ELF格式,并将LOAD段映射到Unicorn的内存中。而在随后的研究中,我们发现目标代码往往会调用其他依赖库中的函数,最常见的就是libc中的各类C标准库函数。通过Unicorn的hook机制,倒是可以将部分标准库函数通过非模拟执行的方式运行。但是这种方式局限太大:假如调用的外部函数不是标准库中的,那么重写实现起来就会非常麻烦。所以,我们还是选择将目标ELF的全部依赖库也一并加载到Unicorn中,并且也通过模拟执行的方式,运行这些依赖库中的代码。
那么,以上所做的,其实也就是Linux中的动态链接器ld.so的工作。Unicorn本身并不包含这些功能,所以一种方式是由Unicorn去模拟执行合适的ld.so,另一种方式是实现相关的解析代码,再调用Unicorn的接口完成映射。由于后一种更可控,所以我们选择了这种方式。不过好在ld.so是开源的,我们只需要把相关的代码修改适配一下即可。最终我们选择了uClibc这个常用于嵌入式设备的轻量库,将其ld.so的代码进行了简单的修改,集成到了uniFuzzer中。
由于我们集成的是ld.so的部分功能,导入函数的地址解析无法在运行时进行。因此,我们采取类似LD_BIND_NOW的方式,在目标ELF和依赖库全部被加载到Unicorn之后,遍历符号地址,并更新GOT表条目。这样,在随后的模拟执行时,就无需再进行导入函数的地址解析工作了。
集成ld.so还带来了一个好处,就是可以利用LD_PRELOAD的机制,实现对库函数的覆盖,这有助于对fuzzing目标进行部分定制化的修改。
设置hook
接下来需要解决的一个重要问题,就是如何获取模拟执行的代码覆盖率,并反馈给LibFuzzer。LibFuzzer和AFL都是在编译目标源码时,通过插桩实现代码覆盖的跟踪。虽然LibFuzzer的具体插桩内容我们还没有分析,但是之前对AFL的分析应该可以作为参考。简单来说,AFL是为每个执行分支生成一个随机数,用于标记当前分支的”位置”;随后在跳转到某个分支时,提取该分支的”位置”,与跳转之前的上一个”位置”作异或,并将异或的结果作为此次跳转的标号,更新一个数组。AFL官网上的文档提供了这一部分的伪代码:

而这个数组,记录的就是每个跳转,如A->B,所发生的次数。AFL以此数组作为代码覆盖率的信息,进行处理,并指导后续的变异。
回到我们的fuzzing工具。如之前所说,LibFuzzer和AFL之所以需要目标的源码,是为了在编译时,在跳转处插入相关的代码,而跳转正好对应的就是基本块这一概念。恰巧,Unicorn提供的hook接口中,也包含了基本块级别的hook,可以在每个基本块被执行之前,回调我们设置的hook函数:

另一方面,通过搜索相关资料,我们发现在LibFuzzer中还神奇地提供了这样一个机制,__libfuzzer_extra_counters:

可见,类似于AFL,通过一个记录跳转发生次数的数组,就可以作为代码覆盖率的信息。作为用户,我们只需要按照格式,声明这样一个数组,并在每次跳转时,更新相应下标处的内容,就可以轻松地将覆盖率信息反馈给LibFuzzer了。
综合以上信息,我们得出了下面的方案:
- 按照extra counters的要求,声明一个
uint8_t类型的数组 - 设置Unicorn对基本块的hook,获取到当前基本块的入口地址,并对应生成一个随机数
- 参考AFL的方式更新数组,将此次跳转的次数加一
其中第2点,为基本块(即分支)生成一个随机数,AFL是在编译插桩时就生成这样的随机数并硬编码的。对于Unicorn来说,如果要实现这样的效果,必须修改Unicorn的源码,在基本块翻译时加入相应的TCG指令。但这样做对Unicorn本身的改动比较大,所以最终我们还是选择通过hook的方式,而尽量不去魔改Unicorn破坏通用性。具体地,我们是将基本块的入口地址计算CRC16哈希,作为其对应的随机数。
准备环境
现在,目标已经加载到Unicorn中,代码覆盖率反馈也已经实现,接下来就只需要准备运行环境了。通过Unicorn的接口,我们可以映射出栈、堆、数据等不同的内存区域,并根据目标代码的需求,设置好相应的寄存器值。
另外,如之前所说,我们移植的ld.so支持通过PRELOAD的方式,覆盖掉要模拟执行的库函数。比如说,目标代码中调用的某些库函数是不必要的,而且由于Unicorn不支持系统调用,所以像printf()这类IO输出的库函数,就可以通过PRELOAD的方式忽略掉,而不影响代码的正常运行。当然,编译的preload库,需要确保其和目标ELF是同一架构、同一符号哈希方式,才能被正确地加载到Unicorn中。
运行fuzzing
准备工作到这里已经完成,接下来就可以fuzzing了。使用LibFuzzer,需要用户实现LLVMFuzzerTestOneInput(const uint8_t *data, size_t len)这个函数,在其中调用要fuzzing的函数,在这里即就是目标代码的Unicorn模拟。根据LibFuzzer生成的输入和其他环境信息,Unicorn开始模拟运行指定的代码片段,并将代码覆盖率通过extra counters数组反馈给LibFuzzer,从而变异生成下一个输入,再次开始下一轮模拟运行。
由于fuzzing时所模拟运行的目标代码片段恒定不变,因此QEMU的JIT机制可以有效地提升运行效率。然而,起初我们测试时,却发现并不是这样:每一轮的模拟执行,都会重新翻译一遍目标代码。经过分析代码,我们发现这是Unicorn的一个坑:为了解决基本块中单步执行遇到的某个问题,Unicorn引入了一个临时解决方案,即在模拟执行停止后,清空QEMU的TB缓存。因此,第二轮模拟执行时,即使是同一段代码,由于缓存被清空,还是需要再重头开始翻译。为了恢复性能,我们需要再注释掉这个临时方案,重新编译安装Unicorn。
示例
我们整理了上述研究结果,实现了一套概念验证代码,其中包含了一个demo。下面我们就以这个demo为例,再次介绍整个fuzzing的运行流程。
demo-vuln.c是要进行fuzzing的目标,其中包含了名为vuln()的函数,存在栈溢出和堆溢出:

可以看到,输入的内容未检查长度,就直接strcpy()到堆上;另外,输入内容的第一个字节作为长度,memcpy()到栈上。
接下来,我们将这段代码编译成32位小端序的MIPS架构ELF。首先我们需要mipsel的交叉编译工具,在Debian上可以安装gcc-mipsel-linux-gnu这个包。接下来运行
mipsel-linux-gnu-gcc demo-vuln.c -Xlinker --hash-style=sysv -no-pie -o demo-vuln
将其编译得到ELF文件demo-vuln。我们要fuzzing的目标,就是其中的vuln()函数。
由于demo-vuln提供了源代码,所以我们看到在vuln()函数中,还调用了printf(), malloc(), strcpy(), memcpy(), free()这些标准库函数。其中printf()如之前所说,可以通过PRELOAD的机制来忽略掉;strcpy()和memcpy(),可以继续模拟执行mipsel架构的libc中的实现;比较复杂的是malloc()和free(),因为一般来说malloc()需要brk()的系统调用,而Unicorn还不支持系统调用。所以,我们也重新写了一个非常简单的堆分配器,并通过PRELOAD的方式替换掉标准库中的实现:
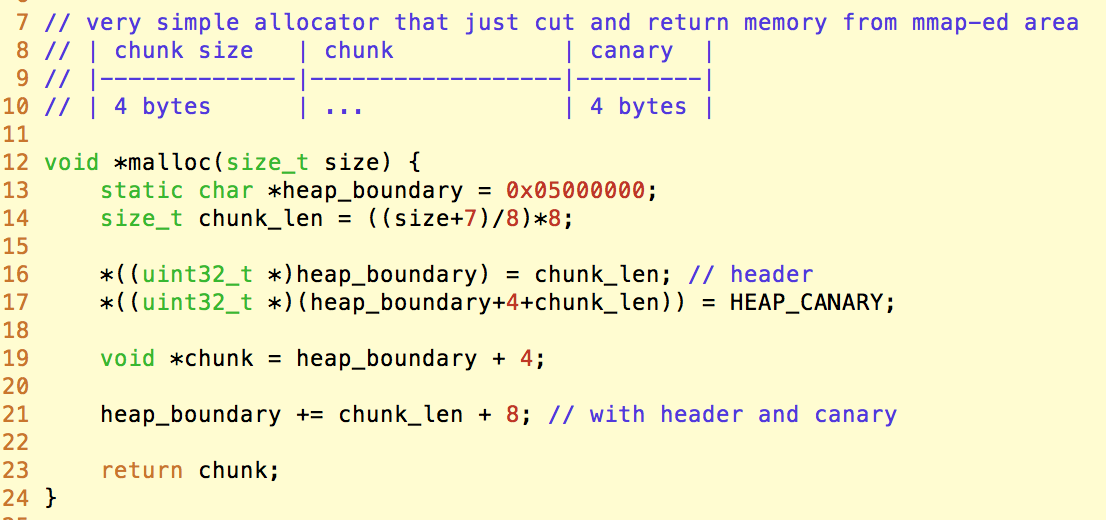
我们需要在Unicorn中分配一片内存作为堆,然后每次malloc()调用,就直接从这片内存中切一块出来。而为了检测可能发生的堆溢出漏洞,我们参考栈溢出检测的机制,在malloc()分配的内存末尾加上一个固定的canary,并在头部写入这块内存的大小,以便后续检查。free()也被简化为空,因此不需要进行内存回收、合并等复杂操作。
接下来,我们将包含上述preload函数的demo-libcpreload.c,也编译成与demo-vuln同样架构的ELF动态库:
mipsel-linux-gnu-gcc -shared -fPIC -nostdlib -Xlinker --hash-style=sysv demo-libcpreload.c -o demo-libcpreload.so
现在,目标ELF和preload库都已经准备完成,接下来就需要编写相关代码,设置好模拟执行的环境。uniFuzzer提供了以下几个回调接口:
void onLibLoad(const char *libName, void *baseAddr, void *ucBaseAddr): 在每个ELF被加载到Unicorn时回调int uniFuzzerInit(uc_engine *uc): 在目标被加载到Unicorn之后回调,可以在这里进行环境的初始化,例如设置堆、栈、寄存器int uniFuzzerBeforeExec(uc_engine *uc, const uint8_t *data, size_t len): 每轮fuzzing执行前回调int uniFuzzerAfterExec(uc_engine *uc): 每轮fuzzing执行完成后回调
用户通过在目录callback/中编写.c代码,实现上述回调函数,进行fuzzing。针对demo-vuln,我们也编写了一个callback/demo-callback.c文件作为参考。
最终,在代码根目录下运行make,即可编译得到最终的fuzzing程序uf。运行以下命令,开始fuzzing:
UF_TARGET=<path to demo-vuln> UF_PRELOAD=<path to demo-libcpreload.so> UF_LIBPATH=<lib path for MIPS> ./uf
相关的参数是通过环境变量传递的。UF_TARGET是要fuzzing的目标ELF文件,UF_PRELOAD是要preload加载的自定义ELF动态库,UF_LIBPATH是依赖库的搜索路径。在Debian上安装libc6-mipsel-cross这个包,应该就会安装所需的mipsel库,此时依赖库的搜索路径就在/usr/mipsel-linux-gnu/lib/。
下图是一个fuzzing触发的崩溃:
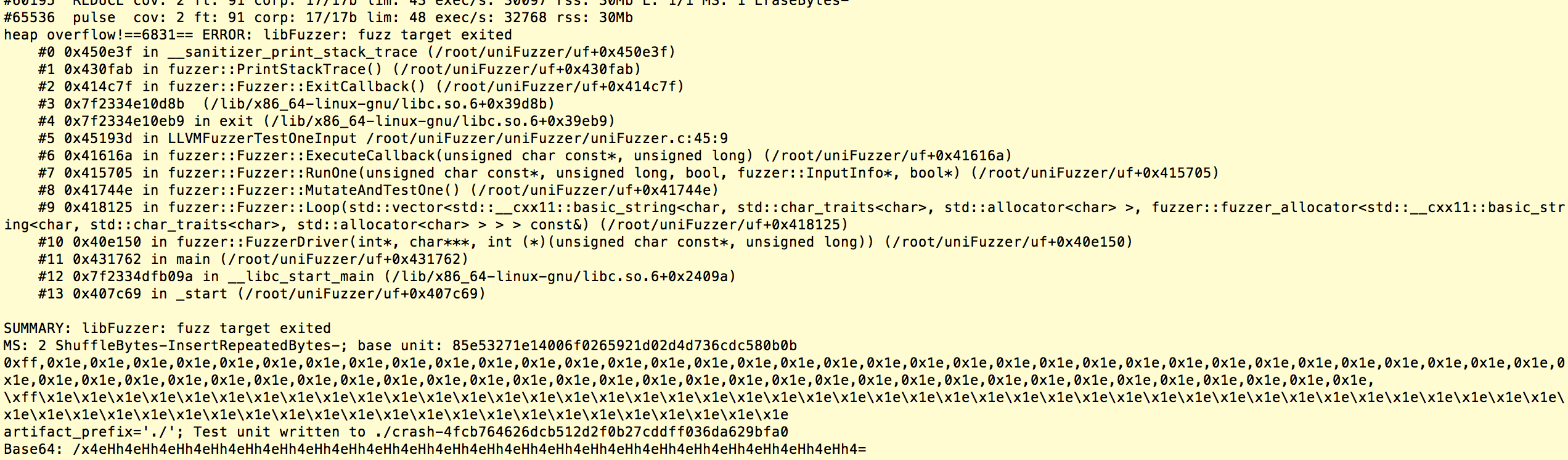
可以看到,uniFuzzer检测到了堆溢出。触发漏洞的,是长度68 bytes的字符串,当其被strcpy()到长度为60 bytes的堆时,canary的值被修改,最终被检测发现。
下图是另一个fuzzing触发的崩溃:
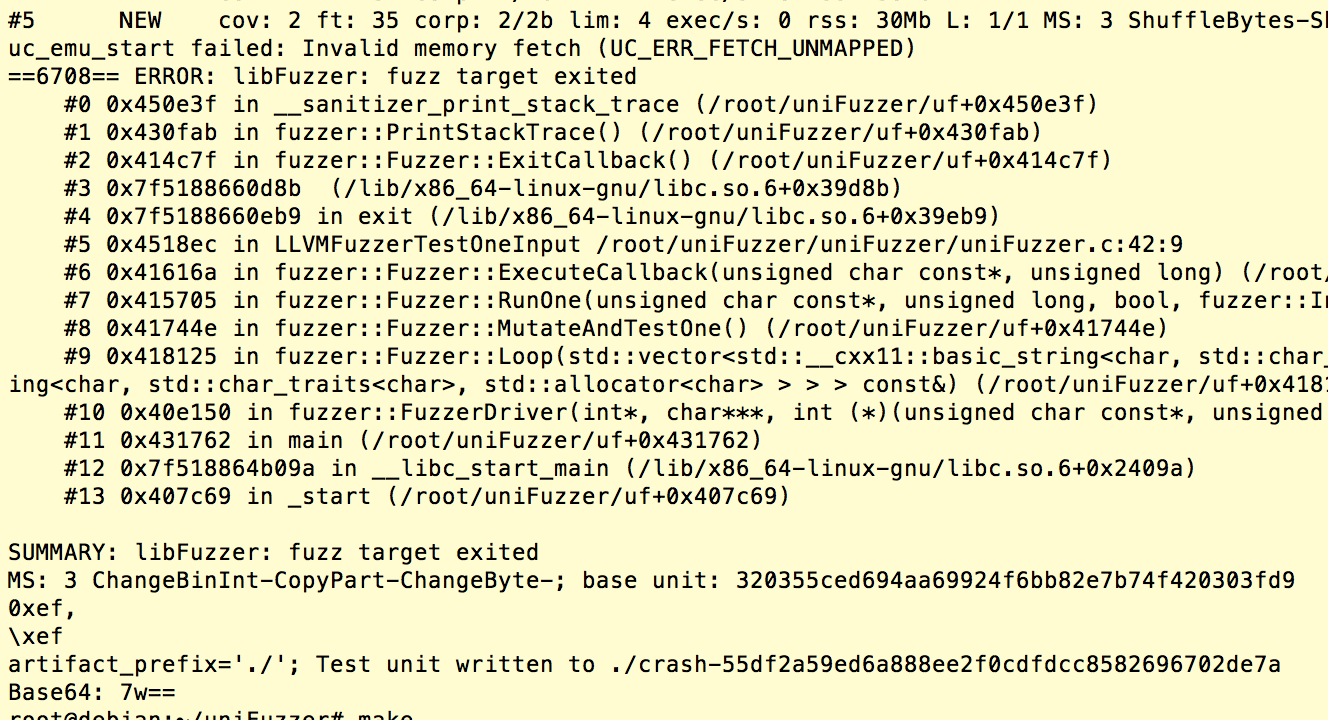
这次的输入只有1个字符,\xef。其被作为memcpy()的参数,复制了超长的内容到128 bytes的栈变量上,从而修改了vuln()函数返回地址,触发了内存访问错误。
总结
通过结合Unicorn和LibFuzzer的功能,我们实现了对闭源代码的fuzzing。上述开源的uniFuzzer代码其实还属于概念验证阶段,许多功能例如系统调用的支持、其他架构/二进制格式的支持等等,还需要后续进一步完善。也欢迎在这方面有研究的小伙伴多提建议和PR,进一步完善功能。